

It is always important to understand different options to solve business challenges. So, let us see how this scenario looks from the perspective of a Salesforce Architect, Consultant, Developer, or an Admin.
Businesses today evolve at a rapid pace; and, organizations demand new features and functionalities to meet compliance, regulatory and other business requirements.
Let us assume that you’re working as a Salesforce Architect at Gurukul on Cloud (GoC). At GoC, during normal times, Order transactions hit 2 million records a week; during peak seasons, however, the range is somewhere between 10-15 million records a week! So, during one of the meetings, GoC’s Compliance Officer shared a business need – retain Opportunity, Order, and Order Transaction Field History data for at least 7 years to meet the organization’s new data retention policy.
Let’s take another example, assume you’re working as a Salesforce Architect at GoC. And, that you are a part of GoC’s Data Governance team. As a result, you have to address the following requirement – Once an Order is Closed, archive the data and keep them available for Salesforce users.
Take a pause and think – how will you solve the above challenges? From the following, which option(s) will you select as a part of your solution?:
- Store data in Heroku Postgres Database and use Heroku Connect to expose it to Salesforce via External Objects.
- Use Cloud, Legacy on-prem database, third party data warehouse (Amazon Redshift, Snowflake, IBM Db2, Google BigQuery, and others) to store the data and then use an interface to expose the data to Salesforce.
- Use AppExchange App (Odaseva, OwnBackup, Spanning Backup, and others) to archive data and use their interface to keep data available in Salesforce.
- Use a simple approach by selecting BigObject to store data and use Lightning Web Component – or an AppExchange application – to make them available to Salesforce users.

When choosing a (or multiple) solution(s), make sure you take the following things into consideration and ensure that your solution is future-proof:
- Volume – Take into consideration data volume by asking a simple question – what is data volume going to look like – a few million, a billion or, a few hundreds of Billions of rows?
- Velocity – When choosing a solution, think about Performance, Query Ability, and how users are going to interact.
- Variety – Consider varieties of data you can store in a given solution – for, as we all know, Salesforce generates different kinds of data when a record is created. For example, when an account is created, Salesforce may create records in AccountShare, AccountTeamMember, etc.
- Value – Understand the value of your investment by measuring the effect a given solution will have on your business (i.e., boosting productivity, providing a competitive advantage); this is vital to determining the solution’s ROI.
In this article, I am going to discuss Big Objects, its Implementation Strategies, and Deployment Steps including some Tips & Tricks to perk things up!
What Are Big Objects?
Big Objects can be used to store and manage enormous amounts (billions of rows) of data on the Salesforce platform. You can use a Big Object to archive Salesforce data or data from external systems.
Big Objects are built on a set of proven big data technologies – Hadoop, Apache Phoenix, etc – with Apache HBase at its core.

There are two types of big objects:
- Standard Big Objects – Standard Big Objects are created by Salesforce and included in Salesforce Products. For example, when you purchase Field Audit Trail Add-on, Salesforce auto-creates/enables FieldHistoryArchive Big Objects.
- Custom Big Objects – We create Custom Big Objects to store information unique to our organization or business requirement(s). Custom Big Object’s API name ends with __b. Use the Metadata API – or Setup – to create Custom Big Objects.
Use Cases for Big Objects
So how does an Enterprise use a Big Object? Here are a few of the most popular Big Objects use cases:
- 360° View Of The Customer – Many Enterprises use Big Objects to build a dashboard application that provides a 360° view of their customers. These dashboards pull data from Big Objects, analyze it and present it to customer service – or sales and/or marketing personnel – in a way that helps them do their jobs better.
- Data Archival – One of the most common – and potentially most cost-effective – ways for Enterprises to begin using Big Objects is to remove some of the historical data from Salesforce or from external data sources. For instance, it may be necessary to maintain historical data to meet compliance requirements.
- Auditing and Tracking – Many Enterprises use Big Objects to track and maintain a long-term view of Salesforce data for audit and compliance purposes.
So, What is the Difference Between a Big Object and a Salesforce Object?
Big Objects and sObjects (Standard and Custom objects) have different properties. Let us pause here for a few, to identify different properties:
| Salesforce Objects (Standard or Custom) | Big Objects |
| Use to store Transactional data | Use to store Non-transactional data |
| Relational database | Horizontally scalable distributed database |
| Use this type of objects to store millions of records | Use this type of objects to store millions to billions of records |
| Support Object and field permission including sharing capabilities | Only support object and field permission |
| Standard or Custom objects can be accessed on Salesforce mobile app | Big Objects can’t be accessed on Salesforce mobile app |
| Support Standard UI (Tabs, Detail Pages, List Views) | Standard UI is unavailable (Tabs, Detail Pages, List Views). Use Lightning Web Component or AppExchange app to bring the data to the UI. |
| Support for Report Builder | No support for Report Builder. Does support Einstein Analytics |
| When a record is created, Salesforce auto generates a record id | When a Big Object record is created, Salesforce doesn’t generate a record id |
Business Use case
Tamara McCleary is working as a Solution Architect at GoC. After learning about Big Objects, she wants to create a Big Object with the following fields to store Opportunity Field History records.
| Field Name | Data Type | Required |
| CreatedById | Text(18) | Yes |
| CreatedDate | Date/Time | Yes |
| DataType | Text(255) | |
| Field | Text(255) | |
| NewValue | Text(255) | |
| OldValue | Text(255) | |
| Opportunity | Lookup(Opportunity) | Yes |
Create a Custom Big Object
Use Metadata API or Salesforce setup to create Big Objects. Perform the following steps to create a Big Object through the setup:
- Navigate to the Setup | ADMINISTRATION | Data | Big Objects.
- Click on the New Button to create a Big Object to store Opportunity Field History records.

- Once done, click on the Save button.
- By default, a Big Object is created with In Development – Deployment Status. To deploy a Big Object, we have to create custom fields and an Index table.

Create Custom Fields
The next step is to create custom fields as mentioned in the business requirement. In the end, it will look like the following screenshot:

Create Index for Custom Big Object
Use custom Index to define the composite primary key (index) for a custom Big Object. While defining a custom index, remember the following:
- Design your primary Key based on how you want to query it.
- The total length for all text fields, in an index, can’t exceed 100 characters.
- Total 5 Fields can be Indexed.
- You have to define an Index Order.
- The field must be required for Indexing.
- Once you create an index it can’t be changed.
- Only one set of Indexes is supported.
- You can not delete a custom index.
Tamara has decided to enable the Indexing for CreatedById, CreatedDate, and Opportunity fields.
Perform the following steps to create a custom Index:
- Navigate to the Index section under OpportunityFieldHistory Big Object.
- Click on New and enable Index for the following fields, as shown below:

- Once done, click on the Save button.

Deploy a Custom Big Object
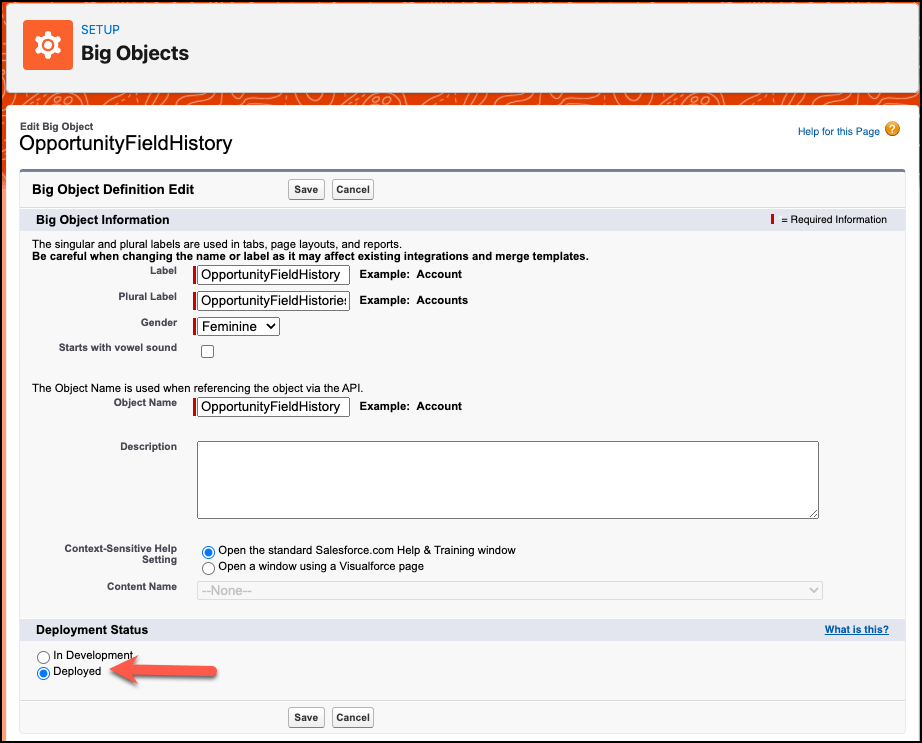
The final step is to deploy the OpportunityFieldHistory Big Object. To do so, perform the following steps:
- Edit OpportunityFieldHistory Big Object
- Select Deployment Status to Deployed, as shown below

- Once done, click on the Save button.
Populate a Custom Big Object with Flow
You can use either Data Loader, Apex, API, or Flow to insert records in Big Objects. Tamara decided she will use the following record triggered flow to insert a record into OpportunityFieldHistory Big Object.

Bring Custom Big Object Records to Salesforce UI
Standard UI like – Tabs, Detail Pages, List Views – nor available for Big Objects. There, you have to use Lightning Web Component or AppExchange app to bring the data from Big Objects to the Salesforce User interface.
Tamara is using the Big Objects Related List AppExchange app to bring the data from OpportunityFieldHistory custom Big Object to related opportunity records.

Move Custom Big Objects from One Org to Another
If you want to move custom Big Objects from one organization to another, use the following tool.
- Change Sets
- Package
- Visual Studio Code
Select Custom Object under Component Type to find custom Big Objects, as shown below:

Things to Remember When Using Big Objects
- The Maximum number of Big Objects per organization can not exceed 100.
- Unless you have an Index, a Big Object can’t be deployed.
- Once created, a Field length can’t be changed.
- FIeld can’t be deleted once you create them.
- Field Data type can’t be changed once created.
- Deleted Big Objects are stored for 15 days.
- There are a few ways to populate a Big Object – (1)You can use a .csv file with Data Loader; do it via API; or, do it entirely through Apex.
- You can’t use Salesforce Connect external objects to access Big Objects in another org.
- Big Objects don’t support encryption. If you archive encrypted data from a standard or custom object, it is stored as clear text on the Big Object.
- Big Objects don’t support transactions. If you want to read – or write – to a Big Object using a trigger, a process, or a flow on an sObject, use asynchronous Apex. Asynchronous Apex has features like the Queueable interface that isolates DML operations on different sObject types to prevent the mixed DML error.
- Deploy Big Objects from one org to another via the following methods:
- Change Set
- Package
- Visual Studio Code
- Use Apex or SOAP API to delete data in a custom Big Object.
- The Big Object SOQL doesn’t support !=, LIKE, NOT IN, EXCLUDES, and INCLUDES operators.
- Aggregate functions are not supported.
Conclusion
As per the Salesforce Add-on pricing document, as of now, Big Objects cost $1000/month for 50 million records. Big Objects can play a key role in data archival decisions – as it allows you to keep everything on the Salesforce platform.
Having read through the blog, feel free to brag about your newly developed expertise of Big Object! And, while you are at it, Go Big!!
Formative Assessment:
I want to hear from you!
What are your secret sauces when it comes to Big Objects? Feel free to share in the comments below.
Proofreader: - Munira Majmundar





How did you use a flow to populate the Big Object?